I've been trying to get my head around this, I've been doing some searching and understand that doing accurate progress calculations is not easy. I even came across this thread where using machine learning is suggested: https://github.com/foosel/OctoPrint/issues/2130
But, for now: can someone explain how OctoPrint calculates it's progress statistics? I frequently feel that the stats I see are way off base. Even if we ignore actual time and just look at percentage.
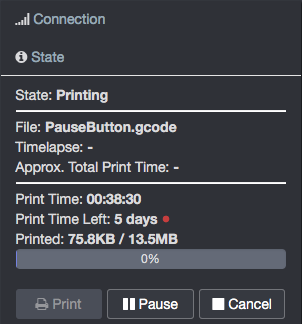
For example, I'n now printing a fairly large object. the print has been running for almost 17 hours and is at layer 530 of 750. OctoPrint shows it's progress at 32%... To me, that seems off... by a lot.
Most of the lower layers are 'simple' (long straight lines) while the last bunch of upper layers include more details and there for more moves (nor per say longer ones).
So... how does OctoPrint come to it's progress?
(as a p.s. I'm very happy with OctoPrint, I run every print through it, go foosel!)
OctoPrint's progress is current position in the file it is printing vs the size of the file it is printing. It might be that your file has a whole bunch of stuff at the end that isn't actually part of the print.
In terms of general estimation, you might be interested in this OctoPrint on Air episode, starting at time 00:44:45, I went into some detail on what OctoPrint does there:
I note that a reasonably-good estimation from my own experience is the following:
b = size of gcode file in bytes
m = minutes to print the file
h = hours to print the file
m = b / (330 * 60)
h = b / (330 * 60 * 60)
So, the file I'm printing now is 4.7MB in size so that's (4.7 * 1024 * 1024) / (330 * 60 * 60) = 4.15 hours and that's a really good estimation of the overall time to print this one since it takes about an hour and a half.
A tiny file is about 170KB and I know that it takes about six and a half minutes to print, from experience. (170 * 1024) / (330 * 60) = 8.8 minutes (which isn't too high)
You indicated in your video that for you know the size of the file and how many bytes of gcode have been processed so far. It sounds like you'd then have exactly what would be required for a simple calculation like that.
Certainly, this is my own experience on my own printer. It's easy enough to confirm for other people. They'd just do the calculation above and compare it with the past print's actual time. If it's close then it sounds like it could work.
@OutsourcedGuru how did you come up with this factor of 330? The problem with something like this is that it most certainly depends on a) the slicer, b) your printer settings (acceleration, jerk, ...) and c) the shape of the model you are printing. Huge base will always be slowed than small base, simply because we print our initial layers slower for better bed adhesion.
Would be interesting indeed though if others can fine similar values that fit their machine/slicer combo. I'm currently travelling, but when I'm back home with the printers I can try to run some numbers based on the available stats.
The 330 comes from a direct measurement of a few prints I've done (variety of stuff like single column, parabolic curve, sphere). Apparently, it's an average bytes-per-second which my printer can do, negating the effects of comments and blocking calls of course.
Even though this works for my printer/setup, that magic number probably should be in the config.yaml, I'm thinking. If the user wants to complain about the accuracy, then you simply invite them to adjust that number in their config by making a quick review of their past print history:
b = sum the file sizes of the last three prints in bytes
s = sum the print times in seconds of the last three prints
b / s = magic number (bytes-per-second rating of their printer)
Does this approach really care if you're printing a pear, a baton or hockey puck? I don't think so. What would matter are "economical" tool paths like "print a 120mm line in the X dimension" which use a small amount of bytes versus the time to implement. So a cube and a sphere would be the two ends of the spectrum, if you think about it.
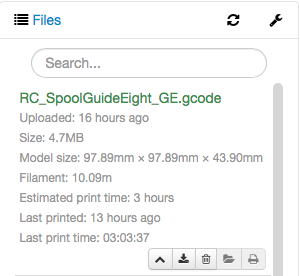
To your credit, OctoPrint's first estimate of "approximately three hours" for my last print was exceedingly close to the actual print time of 3:03 as seen here. (It did range all over the place throughout the 1-2 hour time frame.)
This is where the idea of machine learning could come into play. I saw someone post about that somewhere, just can't remember where, but the idea of sending it all the real world data from your machine and over time it would adjust the estimate method based on environment variables, file data, etc. Well beyond my knowledge, but seems like an interesting approach.
The simplified version of that could be a print history approach where you calculate your general printed volume, file size, temperature heat up time and use the to calculate your "minutes per kb" value.
crowd machine learning would not help much as if I send data about time one g-code took one of my printers to print an object with acceleration of 3000 and junction deviation of 0.9 and same print data from another my printer that has acceleration of 400 and junction deviation of 0.02 the results will be fairly useless..
now, why would you do "machine learning" when you can calculate real time? All you need apart from data already in the file are your machine defaults and some limits. Major 2 values that affect time are acceleration and junction deviation (or jerk if you use marlin or other lesser path generators) assuming that you are not trying to print with speeds that exceed your max print speed. I made a small and simple app that will parse the g-code file and calculate real time according to acceleration and junction deviation settings (if you use marlin just setup acceleration and you will still get better then 1% accurate result) https://github.com/arhi/gcodestat
(in addition to calculate real time to print an object it can upload files directly to octoprint and embed M117 codes inside the file every N% of time progress so that you can see the progress on the display of the screen, there's also a plugin for 1.3.9 octoprint https://github.com/arhi/OctoPrint-gcodestatEstimator that will use this M117 embedded codes and replace original octoprint estimator with a more accurate data)
Any plans on porting/integrating your gcodestat app directly into octoprint to replace it's estimator? I know post processing the gcode file is not a huge pain, but it is still an extra step that would be nice to have as just part of the gcode upload process.
the plugin already replaces the octoprint estimator. parsing the code from estimator is IMO not feasible (other then reading pre-inserted data). I was thinking about inserting some "comments" but found an issue that gcode hook (as expected really) don't pass the comments to the plugins (maybe there is other way to pass comments to plugins but I really was not looking hard ) so I settled with M117 as it works for printer's display too so ..
As for the processing of the code inside the octoprint I do plan to create another plugin that uses octoprint-filemanager-analysis-factory so it replaces the original octoprint analysis with gcodestat so that the file metadata have the info too.... and it can do the whole processing thing in-place after upload, problem is I'm not really a python person so even this existing plugin was done only cause @foosel wrote most of it showing me how to do stuff.. I would have to figure out how to install gcodestat binary on the os (from what I see gcc is not a standard on the images so I need to either prepare binary release on github or somehow trigger installation of gcc and other tools and libs required to compile the gcodestat on the rpi/opi/whatever) and then how to use it from python... rewriting gcodestat in python is 100% not something I will do
anyhow, running gcodestat after saving works great (and easy) from s3d (also uploads the file to the octoprint after processing), from craftware it requires running it manually but since cw don't have auto upload to octoprint I do it in that step... slic3r and cura I use rarely enough to try to figure out how to do it but I assume it should be simple to add the script to them too... so yes, plugin that will run gcodestat will happen, when I figure out how to make it .. for starter will be one that expect gcodestat to be in the path (so you install it however you know how) ... we'll see later on how it will go
 ) so I settled with M117 as it works for printer's display too so ..
) so I settled with M117 as it works for printer's display too so ..